You can perform offline administration tasks using the cmgr command when logged into any CXFS administration node (one that is installed with the cxfs_cluster product) in the pool, or when the GUI is connected to any CXFS administration node in the pool. However, when the filesystems are mounted, administration must be done from the metadata server. (You cannot use cmgr or connect the GUI to a client-only node.)
The following are the same in CXFS and XFS:
Disk concepts
Filesystem concepts
User interface
Filesystem creation
For more information about these topics, see IRIX Admin: Disks and Filesystems.
The rest of this chapter discusses the following topics:
If you have upgraded directly from 6.5.12f or earlier, you must manually convert you filesystem definitions to the new format. See “IRIX: Converting Filesystem Definitions for Upgrades” in Chapter 8.
CXFS can write to real-time files in real-time volumes on IRIX nodes. For more details about real-time volumes, see the XVM Volume Manager Administrator's Guide.
When creating the CXFS filesystem, be aware of the following:
To maintain appropriate performance of the real-time filesystem, do not flag unwritten extents. Use the following command:
irix# mkfs_xfs -d unwritten=0
Set the real-time extent size to a large value for maximum performance.This parameter should be a multiple of the basic filesystem block size, and can vary between 4 KB to 1 GB. SGI recommends 128 MB. You can set this value with the following command:
irix# mkfs_xfs -r extsize=size_of_real-time_extent
Use a large value for block size. Block size can vary between 512 bytes to 64 KB. SGI recommends 16 KB to allow all nodes other than Linux 32-bit to access the filesystem.

Caution: Linux systems are not capable of accessing filesystems with block size larger than the system page size. (The default page sizes are as follows: 4 KB for Linux 32-bit, 16 KB for Linux 64-bit.)
Therefore, if the real-time filesystem is to be accessible by all possible nodes in the cluster, its block size would have to be the lowest possible common denominator (4 KB).You can set this value with the following command:
irix# mkfs_xfs -b size=blocksize
The GUI lets you grant or revoke access to a specific GUI task for one or more specific users. By default, only root may execute tasks in the GUI. Access to the task is only allowed on the node to which the GUI is connected; if you want to allow access on another node in the pool, you must connect the GUI to that node and grant access again.
| Note: You cannot grant or revoke tasks for users with a user ID of 0. |
GUI tasks and the cmgr command operate by executing underlying privileged commands which are normally accessible only to root. When granting access to a task, you are in effect granting access to all of its required underlying commands, which results in also granting access to the other GUI tasks that use the same underlying commands.
For instructions about granting or revoking GUI privileges, see “Privileges Tasks with the GUI” in Chapter 10.
To see which tasks a specific user can currently access, select View: Users. Select a specific user to see details about the tasks available to that user.
To see which users can currently access a specific task, select View: Task Privileges. Select a specific task to see details about the users who can access it and the privileged commands it requires.
If you are upgrading to 6.5.19f from 6.5.17f or earlier and you want to change an existing node with weight 1 (which as of 6.5.18f was defined as a server-capable administration node) to be a client-only node, you must do the following:
Ensure that the node is not listed as a potential metadata server for any filesystem. See “Modify a CXFS Filesystem with the GUI” in Chapter 10, or “Modify a CXFS Filesystem with cmgr” in Chapter 11.
Stop the CXFS services on the node. See “Stop CXFS Services (Normal CXFS Shutdown) with the GUI” in Chapter 10, or “Stop CXFS Services with cmgr” in Chapter 11.
Modify the cluster so that it no longer contains the node. See “Modify a Cluster Definition with the GUI” in Chapter 10, or “Modify a Cluster with cmgr” in Chapter 11.
Delete the node definition. See “Delete a Node with the GUI” in Chapter 10, or “Delete a Node with cmgr” in Chapter 11.
Install the node with the cxfs_client package and remove the cluster_admin, cluster_control, and cluster_services packages. See“IRIX Client-only Software Installation” in Chapter 6.
Reboot the node to ensure that all previous node configuration information is removed.
Redefine the node and use a node function of client-only. See “Define a Node with the GUI” in Chapter 10, or “Define a Node with cmgr” in Chapter 11.
Modify the cluster so that it contains the node. See “Modify a Cluster Definition with the GUI” in Chapter 10, or “Modify a Cluster with cmgr” in Chapter 11.
Start the CXFS services on the node. See “Start CXFS Services with the GUI” in Chapter 10, or “Start CXFS Services with cmgr” in Chapter 11.
When you install CXFS, the following default scripts are placed in the appropriate directory:
On server-capable nodes:
/var/cluster/clconfd-scripts/cxfs-pre-mount
/var/cluster/clconfd-scripts/cxfs-post-mount
/var/cluster/clconfd-scripts/cxfs-pre-umount
/var/cluster/clconfd-scripts/cxfs-post-umount
The clconfd daemon executes the above scripts.
On client-only nodes:
/var/cluster/cxfs_client-scripts/cxfs-pre-mount
/var/cluster/cxfs_client-scripts/cxfs-post-mount
/var/cluster/cxfs_client-scripts/cxfs-pre-umount
/var/cluster/cxfs_client-scripts/cxfs-post-umount
The cxfs_client daemon executes the above scripts.
These scripts allow you to use NFS to export the CXFS filesystems listed in /etc/exports if they are successfully mounted. The scripts also ensure that LUN path failover works properly after fencing by executing the following:
/etc/init.d/failover stop /etc/init.d/failover start |
The appropriate daemon executes these scripts before and after mounting or unmounting CXFS filesystems specified in the /etc/exports file. The files must be named exactly as above and must have root execute permission.
| Note: The /etc/exports file describes the filesystems
that are being exported to NFS clients. If a CXFS mount point is included
in the exports file, the empty mount point is exported
unless the filesystem is re-exported after the CXFS mount using the
cxfs-post-mount script.
The /etc/exports file cannot contain any filesystems managed by FailSafe. |
The following arguments are passed to the files:
cxfs-pre-mount: filesystem device name
cxfs-post-mount: filesystem device name and exit code
cxfs-pre-umount: filesystem device name
cxfs-post-umount: filesystem device name and exit code
Because the filesystem name is passed to the scripts, you can write the scripts so that they take different actions for different filesystems; because the exit codes are passed to the post files, you can write the scripts to take different actions based on success or failure of the operation.
The clconfd or cxfs_client daemon checks the exit code for these scripts. In the case of failure (nonzero), the following occurs:
For cxfs-pre-mount and cxfs-pre-umount , the corresponding mount or unmount is not performed.
For cxfs-post-mount and cxfs-post-umount , clconfd will retry the entire operation (including the -pre- script) for that operation.
This implies that if you do not want a filesystem to be mounted on a host, the cxfs-pre-mount script should return a failure for that filesystem while the cxfs-post-mount script returns success.
The following script is run when needed to reprobe the Fibre Channel controllers:
On server-capable nodes:
/var/cluster/clconfd-scripts/cxfs-reprobe
On client-only nodes:
/var/cluster/cxfs_client-scripts/cxfs-reprobe
You may modify any of these scripts if needed.
You must unmount lofs mounts of a CXFS filesystem before attempting to unmount the CXFS filesystem. You can use a script such as the following to unexport and locally unmount an lofs filesystem:
#!/bin/ksh
#/var/cluster/clconfd-scripts/cxfs-pre-umount
echo "$0: Preparing to unmount CXFS file system \"$1\""
MNTPNT=`mount | grep "$1 " | cut -f 3 -d" "`
print "MNTPNT $MNTPNT"
if [ -n "${MNTPNT}" ] ; then
lofslist=`mount | grep 'type lofs' | grep "${MNTPNT}" | nawk '{print $3}'`
set -e
for lofs in ${lofslist}
do
echo "$0: unmounting $lofs"
umount -k $lofs
done
if /usr/etc/exportfs | /sbin/grep -q "${MNTPNT}" ; then
echo "$0: unexporting $MNTPNT"
/usr/etc/exportfs -u ${MNTPNT}
fi
fi |
If there are problems with a node, the I/O fencing software sends a message via the telnet protocol to the appropriate Fibre Channel switch. The switch only allows one telnet session at a time; therefore, if you are using I/O fencing, you must keep the telnet port on the Fibre Channel switch free at all times. Do not perform a telnet to the switch and leave the session connected.
The IRIX fsr and the Linux 64-bit xfs_fsr commands can only be used on the active metadata server for the filesystem; the bulkstat system call has been disabled for CXFS clients. You should use fsr or xfs_fsr manually, and only on the active metadata server for the filesystem.
The cron daemon can cause severe stress on a CXFS filesystem if multiple nodes in a cluster start the same filesystem-intensive task simultaneously. An example of such a task is one that uses the find command to search files in a filesystem.
Any task initiated using cron on a CXFS filesystem should be launched from a single node in the cluster, preferably from the active metadata server.
CXFS supports the use of hierarchical storage management (HSM) products through the data management application programming interface (DMAPI), also know as X/Open Data Storage Management Specification (XSDM). An example of an HSM product is the Data Migration Facility (DMF). DMF is the only HSM product currently supported with CXFS.
| Note: CXFS does not support the relocation or recovery of DMAPI filesystems that are being served by Linux 64-bit metadata servers. |
The HSM application must make all of its DMAPI interface calls through the active metadata server. The CXFS client nodes do not provide a DMAPI interface to CXFS mounted filesystems. A CXFS client routes all of its communication to the HSM application through the metadata server. This generally requires that the HSM application run on the CXFS metadata server.
To use HSM with CXFS, do the following:
Install eoe.sw.dmi on each CXFS administration node. For client-only nodes, no additional software is required.
Use the dmi option when mounting a filesystem to be managed. For more information about this step, see “Define CXFS Filesystems with the GUI” in Chapter 10, or “Modify a Cluster with cmgr” in Chapter 11.
Start the HSM application on the active metadata server for each filesystem to be managed.
You can discover the active metadata server using the GUI or the cluster_status or clconf_info commands.
Select View: Filesystems
In the view area, click the name of the filesystem you wish to view. The name of the active metadata server is displayed in the details area to the right.
Figure 12-1 shows an example.
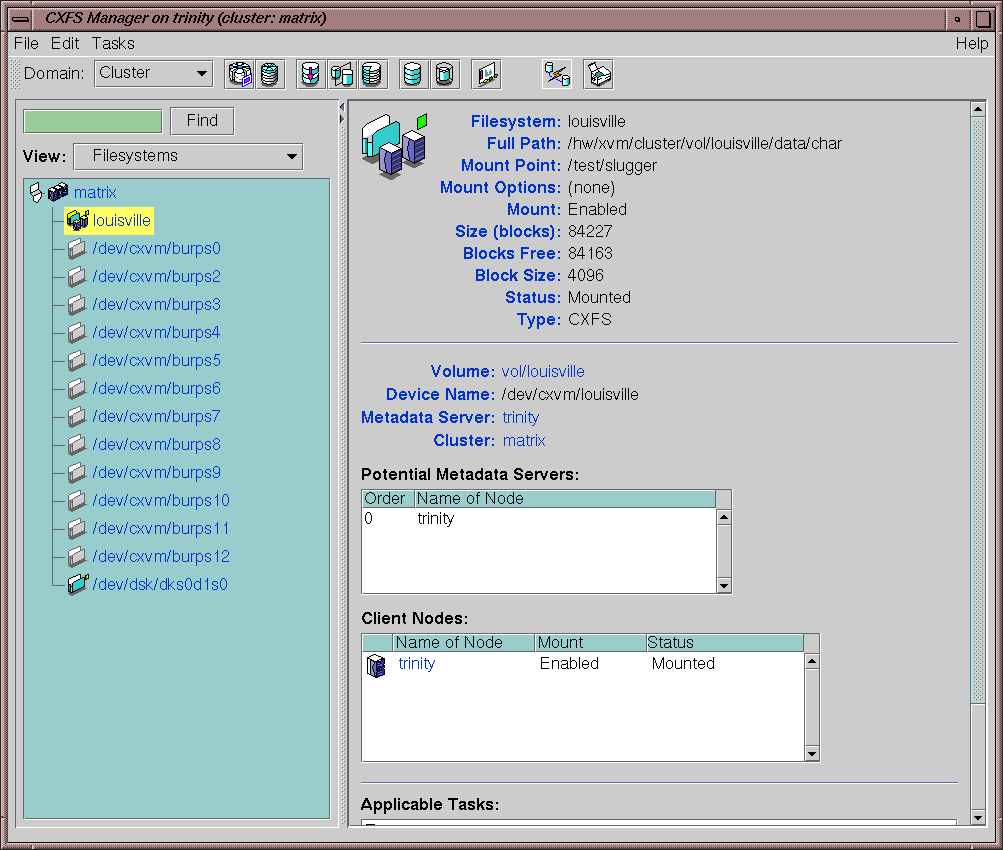
You can use the cluster_status command to discover the active metadata server. For example:
# /var/cluster/cmgr-scripts/cluster_status
+ Cluster=cxfs6-8 FailSafe=Not Configured CXFS=ACTIVE 15:15:33
Nodes = cxfs6 cxfs7 cxfs8
FailSafe =
CXFS = UP UP UP
CXFS DevName MountPoint MetaServer Status
/dev/cxvm/concat0 /concat0 cxfs7 UP |
For more information, see “Check Cluster Status with cluster_status” in Chapter 16.
You can use the clconf_info command to discover the active metadata server for a given filesystem. For example, the following shows that cxfs7 is the metadata server:
cxfs6 # clconf_info Membership since Thu Mar 1 08:15:39 2001 Node NodeId Status Age Incarnation CellId cxfs6 6 UP 0 0 2 cxfs7 7 UP 0 0 1 cxfs8 8 UP 0 0 0 1 CXFS FileSystems /dev/cxvm/concat0 on /concat0 enabled server=(cxfs7) 2 client(s)=(cxfs8,cxfs6) |
| Note: Recovery is supported only when using standby nodes. |
If the node acting as the metadata server for a filesystem dies, another node in the list of potential metadata servers will be chosen as the new metadata server. This assumes that at least two potential metadata servers are listed when you define a filesystem. For more information, see “Define CXFS Filesystems with the GUI” in Chapter 10, or “Modify a Cluster with cmgr” in Chapter 11.
The metadata server that is chosen must be a filesystem client; other filesystem clients will experience a delay during the relocation process. Each filesystem will take time to recover, depending upon the number of active inodes; the total delay is the sum of time required to recover each filesystem. Depending on how active the filesystems are at the time of recovery, the total delay could take up to several minutes per filesystem.
If a CXFS client dies, the metadata server will clean up after the client. Other CXFS clients may experience a delay during this process. A delay depends on what tokens, if any, that the deceased client holds. If the client has no tokens, then there will be no delay; if the client is holding a token that must be revoked in order to allow another client to proceed, then the other client will be held up until recovery returns the failed nodes tokens (for example, in the case where the client has the write token and another client wants to read). The actual length of the delay depends upon the following:
The total number of exported inodes on the metadata server
CXFS kernel membership situation
Whether any servers have died
Where the servers are in the recovery order relative to recovering this filesystem
The deceased CXFS client is not allowed to rejoin the CXFS kernel membership until all metadata servers have finished cleaning up after the client.
This section tells you how to perform the following:
If there are problems, see Chapter 18, “Troubleshooting”. For more information about states, Chapter 16, “Monitoring Status”.
A cluster database shutdown terminates the following user-space daemons that manage the cluster database:
cad
clconfd
cmond
crsd
fs2d
After shutting down the database on a node, access to the shared filesystems remains available and the node is still a member of the cluster, but the node is not available for database updates. Rebooting of the node results in a restart of all services.
To perform a cluster database shutdown, enter the following:
# /etc/init.d/cxfs_cluster stop |
If you also want to disable the daemons from restarting at boot time, enter the following:
# chkconfig cluster off |
A cluster database shutdown is appropriate when you want to perform a maintenance operation on the node and then reboot it, returning it to ACTIVE status.
If you perform a cluster database shutdown, the node status will be DOWN, which has the following impacts:
The DOWN node is still considered part of the cluster, but unavailable.
The DOWN node does not get cluster database updates; however, it will be notified of all updates after it is rebooted.
Missing cluster database updates can cause problems if the kernel portion of CXFS is active. That is, if the node continues to have access to CXFS, the node's kernel level will not see the updates and will not respond to attempts by the remaining nodes to propagate these updates at the kernel level. This in turn will prevent the cluster from acting upon the configuration updates.
You should perform a normal CXFS shutdown when you want to stop all CXFS services on a node and remove it from the CXFS kernel membership quorum. A normal CXFS shutdown does the following:
Unmounts all the filesystems except those for which it is the active metadata server; those filesystems for which the node is the active metadata server will become inaccessible from the node after it is shut down.
Terminates the CXFS kernel membership of this node in the cluster.
Marks the node as INACTIVE.
The effect of this is that cluster disks are unavailable and no cluster database updates will be propagated to this node. Rebooting the node leaves it in the shutdown state.
If the node on which you shut down CXFS services is an active metadata server for a filesystem, then that filesystem will be recovered by another node that is listed as one of its potential metadata servers. For more information, see “Define CXFS Filesystems with the GUI” in Chapter 10, or “Modify a Cluster with cmgr” in Chapter 11. The server that is chosen must be a filesystem client; other filesystem clients will experience a delay during the recovery process.
If the node on which the CXFS shutdown is performed is the sole potential metadata server (that is, there are no other nodes listed as potential metadata servers for the filesystem), then you should use the CXFS GUI or the cmgr command to unmount the filesystem from all nodes before performing the shutdown.
To perform a normal CXFS shutdown, enter the following cmgr command:
cmgr> stop cx_services on node nodename for cluster clustername |
You could also use the GUI; see “Stop CXFS Services (Normal CXFS Shutdown) with the GUI” in Chapter 10.
| Note: This action deactivates CXFS services on one
node, forming a new CXFS kernel membership after deactivating the node.
If you want to stop services on multiple nodes, you must enter this command
multiple times or perform the task using the GUI.
After you shut down cluster services on a node, the node is marked as inactive and is no longer used when calculating the CXFS kernel membership. See “Node Status” in Chapter 16. |
After performing normal CXFS shutdown on a node, its state will be INACTIVE; therefore, it will not impact CXFS kernel membership quorum calculation. See “Normal CXFS Shutdown”.
You should not perform a normal CXFS shutdown under the following circumstances:
On the local node, which is the CXFS administration node on which the cluster manager is running or the node to which the GUI is connected
If stopping CXFS services on the node will result in loss of CXFS kernel membership quorum
If the node is the only available metadata server for one or more active CXFS filesystems
If you want to perform a CXFS shutdown under these conditions, you must perform a forced CXFS shutdown. See “Forced CXFS Shutdown: Revoke Membership of Local Node”.
The node will not rejoin the cluster after a reboot. The node will rejoin the cluster only when CXFS services are explicitly reactivated with the GUI (see “Start CXFS Services with the GUI” in Chapter 10) or the following command:
cmgr> start cx_services on node nodename for cluster clustername |
A forced CXFS shutdown is appropriate when you want to shutdown the local node even though it may drop the cluster below its CXFS kernel membership quorum requirement.
CXFS does the following:
Shuts down all cluster filesystems on the local node
Attempts to access the cluster filesystems result in I/O error (you may need to manually unmount the filesystems)
Removes this node from the CXFS kernel membership
Marks the node as DOWN
| Caution: A forced CXFS shutdown may cause the cluster to fail if the cluster drops below CXFS kernel membership quorum. |
If you do a forced shutdown on an active metadata server, it loses membership immediately. At this point another potential metadata server must take over (and recover the filesystems) or quorum is lost and a forced shutdown follows on all nodes.
If you do a forced CXFS shutdown that forces a loss of quorum, the remaining part of the cluster (which now must also do a forced shutdown) will not reset the departing node.
To perform a forced CXFS shutdown, enter the following cmgr command to revoke the CXFS kernel membership of the local node:
cmgr> admin cxfs_stop |
You can also perform this action with the GUI; see “Revoke Membership of the Local Node with the GUI” in Chapter 10. This action can also be triggered automatically by the kernel after a loss of CXFS kernel membership quorum.
After a forced CXFS shutdown, the node is still considered part of the configured cluster and is taken into account when propagating the cluster database (these services are still running) and when computing the cluster database (fs2d) membership quorum (this could cause a loss of quorum for the rest of the cluster, causing the other nodes to do a forced shutdown). The state is INACTIVE.
It is important that this node stays accessible and keeps running the cluster infrastructure daemons to ensure database consistency. In particular, if more than half the nodes in the pool are down or not running the infrastructure daemons, cluster database updates will stop being propagated and will result in inconsistencies. To be safe, you should remove those nodes that will remain unavailable from the cluster and pool. See:
After a forced CXFS shutdown, the local node will not resume CXFS kernel membership until the node is rebooted or until you explicitly allow CXFS kernel membership for the local node by entering the following cmgr command:
cmgr> admin cxfs_start |
You can also perform this step with the GUI; see “Allow Membership of the Local Node with the GUI” in Chapter 10.
If you perform a forced shutdown on a CXFS administration node, you must restart CXFS on that node before it can return to the cluster. If you do this while the cluster database still shows that the node is in a cluster and is activated, the node will restart the CXFS kernel membership daemon. Therefore, you may want to do this after resetting the database or after stopping CXFS services.
For example:
cmgr> admin cxfs_start |
| Caution: If you perform forced shutdown on an administration node with reset capability and the shutdown will not cause loss of cluster quorum, the node will be reset (rebooted) by the appropriate node. |
For more information about resets, see “Reset” in Chapter 1.
The IRIX cxfs_cluster flag and the Linux 64-bit cxfs flag to chkconfig controls the clconfd daemon on a CXFS administration node. The cxfs_client flag controls the cxfs_client daemon on a client-only node. On Linux 64-bit nodes, chkconfig settings are saved by updating various symbolic links in the /etc/rc.n directories.
If these settings are turned off, the daemons will not be started at the next reboot and the kernel will not be configured to join the cluster. It is useful to turn them off before rebooting if you want to temporarily remove the nodes from the cluster for system or hardware upgrades or for other maintenance work.
To avoid restarting the cluster database on a CXFS administration node, set the cluster option to off.
For example, do the following:
IRIX administration node:
irix# /etc/chkconfig cxfs_cluster off irix# /etc/chkconfig cluster off irix# reboot
Linux 64-bit administration node:
[root@linux64 root]# /sbin/chkconfig cxfs off [root@linux64 root]# /sbin/chkconfig cluster off [root@linux64 root]# reboot
You should rotate the log files at least weekly so that your disk will not become full. The following sections provide example scripts. For information about log levels, see “Configure Log Groups with the GUI” in Chapter 10.
You can run the /var/cluster/cmgr-scripts/rotatelogs script to copy all files to a new location. This script saves log files with the day and the month name as a suffix. If you run the script twice in one day, it will append the current log file to the previous saved copy. The root crontab file has an entry to run this script weekly.
The script syntax is as follows:
/var/cluster/cmgr-scripts/rotatelogs [-h] [-d|-u] |
If no option is specified, the log files will be rotated. Options are as follows:
| -h | Prints the help message. The log files are not rotated and other options are ignored. |
| -d | Deletes saved log files that are older than one week before rotating the current log files. You cannot specify this option and -u. |
| -u | Unconditionally deletes all saved log files before rotating the current log files. You cannot specify this option and -d . |
By default, the rotatelogs script will be run by crontab once a week, which is sufficient if you use the default log levels. If you plant to run with a high debug level for several weeks, you should reset the crontab entry so that the rotatelogs script is run more often.
On heavily loaded machines, or for very large log files, you may want to move resource groups and stop CXFS services before running rotatelogs.
You can use a script such as the following to copy large files to a new location. The files in the new location will be overwritten each time this script is run.
#!/bin/sh
# Argument is maximum size of a log file (in characters) - default: 500000
size=${1:-500000}
find /var/cluster/ha/log -type f ! -name '*.OLD' -size +${size}c -print | while read log_file; do
cp ${log_file} ${log_file}.OLD
echo '*** LOG FILE ROTATION ' `date` '***' > ${log_file}
done |
Also see “cad.options on CXFS Administration Nodes” in Chapter 8, and “fs2d.options on CXFS Administration Nodes ” in Chapter 8
CXFS uses the XVM volume manager. XVM can combine many disks into high transaction rate, high bandwidth, and highly reliable filesystems. CXFS uses XVM to provide the following:
For more information, see the XVM Volume Manager Administrator's Guide.
This section describes the CXFS differences for backups, NFS, Quotas, and Samba.
CXFS enables the use of commercial backup packages such as VERITAS NetBackup and Legato NetWorker for backups that are free from the local area network (LAN), which allows the backup server to consolidate the backup work onto a backup server while the data passes through a storage area network (SAN), rather than through a lower-speed LAN.
For example, a backup package can run on a host on the SAN designated as a backup server. This server can use attached tape drives and channel connections to the SAN disks. It runs the backup application, which views the filesystems through CXFS and transfers the data directly from the disks, through the backup server, to the tape drives.
This allows the backup bandwidth to scale to match the storage size, even for very large filesystems. You can increase the number of disk channels, the size of the backup server, and the number of tape channels to meet the backup-bandwidth requirements.
You can put an NFS server on top of CXFS so that computer systems that are not part of the cluster can share the filesystems. This can be performed on any node.
XFS quotas are supported. However, the quota mount options must be the same on all mounts of the filesystem. You can administer quotas from any IRIX or Linux 64-bit node in the cluster that has the quota administration software installed. You must install the quota administration software on the potential server administration nodes in the cluster.
You can run Samba on top of CXFS, allowing Windows machines to support CXFS and have access to the filesystem. However, you should not use multiple Samba servers.
The architecture of Samba assumes that each share is exported by a single server. Because all Samba client accesses to files and directories in that share are directed through a single Samba server, the Samba server is able to maintain private metadata state to implement the required concurrent access controls (in particular, share modes, write caching and oplock states). This metadata is not necessarily promulgated to the filesystem and there is no protocol for multiple Samba servers exporting the same share to communicate this information between them.
Running multiple Samba servers on one or more CXFS (or NFS) clients exporting a single share that maps to a common underlying filesystem has the following risks:
File data corruption from writer-writer concurrency
Application failure due to inconsistent file data from writer-reader concurrency
These problems do not occur when a single Samba server is deployed, because that server maintains a consistent view of the metadata used to control concurrent access across all Samba clients.
It is possible to deploy multiple Samba servers only under one of the following circumstances:
There are no writers, so a read-only share is exported
Application-level protocols and/or work-flow guarantee that only one application is ever writing a file, and concurrent file writing and reading does not take place
In one of the above cases, you could (for example) turn oplock support off in the Samba servers.
| Caution: The onus is on the customer to ensure these conditions are met, as there is nothing in the Samba architecture to verify it. Therefore, SGI recommends that you do not use multiple Samba servers. |
Although filesystem information is traditionally stored in /etc/fstab , the CXFS filesystems information is relevant to the entire cluster and is therefore stored in the replicated cluster database instead.
As the administrator, you will supply the CXFS filesystem configuration by using the CXFS Cluster Manager tools. For information about the GUI, see “Filesystem Tasks with the GUI” in Chapter 10; for information about cmgr , see “Cluster Tasks with cmgr” in Chapter 11.
The information is then automatically propagated consistently throughout the entire cluster. The cluster configuration daemon mounts the filesystems on each node according to this information, as soon as it becomes available.
A CXFS filesystem will be automatically mounted on all the nodes in the cluster. You can add a new CXFS filesystem to the configuration when the cluster is active.
Whenever the cluster configuration daemon detects a change in the cluster configuration, it does the equivalent of a mount -a command on all the filesystems that are configured.
| Caution: You must not modify or remove a CXFS filesystem definition while the filesystem is mounted. You must unmount it first and then mount it again after the modifications. |
You supply mounting information with the GUI Mount a Filesystem task (which is part of the Set Up a New Filesystem guided configuration task) or with the modify subcommand to cmgr(1M). See the following:
For information about mounting using the GUI, see “Set Up a New CXFS Filesystem with the GUI” in Chapter 9, and “Define CXFS Filesystems with the GUI” in Chapter 10.
For information about defining and mounting a new filesystem with cmgr, see “Modify a Cluster with cmgr” in Chapter 11.
For information about mounting a filesystem that has already been defined but is currently unmounted, see “Define a CXFS Filesystem with cmgr” in Chapter 11.
When properly defined and mounted, the CXFS filesystems are automatically mounted on each node by the local cluster configuration daemon, clconfd, according to the information collected in the replicated database. After the filesystems configuration has been entered in the database, no user intervention is necessary.
| Caution: Do not attempt to use the mount command to mount a CXFS filesystem. Doing so can result in data loss and/or corruption due to inconsistent use of the filesystem from different nodes. |
Mount points cannot be nested when using CXFS. That is, you cannot have a filesystem within a filesystem, such as /usr and /usr/home.
To unmount CXFS filesystems, use the GUI Unmount a Filesystem task or the admin subcommand to cmgr. For information, see “Unmount CXFS Filesystems with the GUI” in Chapter 10, or “Unmount a CXFS Filesystem with cmgr” in Chapter 11.
These tasks unmount a filesystem from all nodes in the cluster. Although this action triggers an unmount on all the nodes, some might fail if the filesystem is busy. On active metadata servers, the unmount cannot succeed before all of the CXFS clients have successfully unmounted the filesystem. All nodes will retry the unmount until it succeeds, but there is no centralized report that the filesystem has been unmounted on all nodes.
To verify that the filesystem has been unmounted from all nodes, do one of the following:
Check the SYSLOG files on the metadata servers for a message indicating that the filesystem has been unmounted.
Run the GUI or cmgr on the metadata server, disable the filesystem from the server, and wait until the GUI shows that the filesystem has been fully disabled. (It will be an error if it is still mounted on some CXFS clients and the GUI will show which clients are left.)
To grow a CXFS filesystem, do the following:
Unmount the CXFS filesystem. For information, see “Unmount CXFS Filesystems with the GUI” in Chapter 10, or “Unmount a CXFS Filesystem with cmgr” in Chapter 11.
Mount the filesystem as an XFS filesystem. See IRIX Admin: Disks and Filesystems.
Use the xfs_growfs command or the GUI task; see “Grow a Filesystem with the GUI” in Chapter 10.
Unmount the XFS filesystem with the umount command.
Mount the filesystem as a CXFS filesystem. See “Mount CXFS Filesystems with the GUI” in Chapter 10, or “Define a CXFS Filesystem with cmgr” in Chapter 11.
You must perform dump and restore procedures from the active metadata server. The xfsdump and xfsrestore commands make use of special system calls that will only function on the metadata server.
The filesystem can have active clients during a dump process.
In a clustered environment, a CXFS filesystem may be directly accessed simultaneously by many CXFS clients and the active metadata server. With failover or simply metadata server reassignment, a filesystem may, over time, have a number of metadata servers. Therefore, in order for xfsdump to maintain a consistent inventory, it must access the inventory for past dumps, even if this information is located on another node.
SGI recommends that the inventory be made accessible by potential metadata server nodes in the cluster using one of the following methods:
Relocate the inventory to a shared filesystem.
For example, where shared_filesystem is replaced with the actual name of the filesystem to be shared:
On the node currently containing the inventory, enter the following:
# cd /var # cp -r xfsdump /shared_filesystem # mv xfsdump xfsdump.bak # ln -s /shared_filesystem/xfsdump xfsdump
On all other administration nodes in the cluster, enter the following:
# cd /var # mv xfsdump xfsdump.bak # ln -s /shared_filesystem/xfsdump xfsdump
Export the directory using an NFS shared filesystem.
For example:
On the IRIX node currently containing the inventory, add /var/xfsdump to /etc/exports and then enter the following:
irix# exportfs -a
(On a Linux 64-bit, the path is /var/lib/xfsdump.)
On all other IRIX administration nodes in the cluster, enter the following:
# cd /var # mv xfsdump xfsdump.bak # ln -s /hosts/hostname/var/xfsdump xfsdump
| Note: It is the IRIX /var/xfsdump directory (Linux 64-bit /var/lib/xfsdump) that should be shared, rather than the IRIX /var/xfsdump/inventory directory (Linux 64-bit /var/lib/xfsdump/inventory). If there are inventories stored on various nodes, you can use xfsinvutil to merge them into a single common inventory, prior to sharing the inventory among the cluster. |
CXFS has the following flags to the chkconfig command:
On administration nodes, cluster controls the other cluster administration daemons, such as the replicated cluster database. If it is turned off, the database daemons will not be started at the next reboot and the local copy of the database will not be updated if you make changes to the cluster configuration on the other nodes. This could cause problems later, especially if a majority of nodes are not running the database daemons. If the database daemons are not running, the cluster database will not be accessible locally and the node will not be configured to join the cluster.
On administration nodes, a flag controls the clconfd daemon and whether or not the cxfs_shutdown command is used during a system shutdown. The cxfs_shutdown command attempts to withdraw from the cluster gracefully before rebooting. Otherwise, the reboot is seen as a failure and the other nodes have to recover from it.
The flag name differs between the operating systems:
IRIX: cxfs_cluster
Linux 64-bit: cxfs
On client-only nodes, the cxfs_client flag controls whether or not the cxfs_client daemon should be started.
Table 12-1 shows the system tunable parameters available with CXFS. You can use the sysctl command to manipulate these parameters. On IRIX you can also use the systune command.
Table 12-1. System Tunable Parameters
On Origin 300, Origin 3200C, Onyx 300, and Onyx 3200C systems, there is only one serial/USB port that provides both L1 system controller and console support for the machine. In a CXFS configuration, this port (the DB9 connector) is used for system reset. It is connected to a serial port in another node or to the Ethernet multiplexer.
To get access to console input and output, you must redirect the console to another serial port in the machine.
Use the following procedure to redirect the console:
Edit the /etc/inittab file to use an alternate serial port.
Either issue an init q command or reboot.
For example, suppose you had the following in the IRIX /etc/inittab file (line breaks added for readability):
# on-board ports or on Challenge/Onyx MP machines, first IO4 board ports t1:23:respawn:/sbin/suattr -C CAP_FOWNER,CAP_DEVICE_MGT,CAP_DAC_WRITE+ip -c "exec /sbin/getty ttyd1 console" # alt console t2:23:off:/sbin/suattr -C CAP_FOWNER,CAP_DEVICE_MGT,CAP_DAC_WRITE+ip -c "exec /sbin/getty -N ttyd2 co_9600" # port 2 |
You could change it to the following:
# on-board ports or on Challenge/Onyx MP machines, first IO4 board ports t1:23:off:/sbin/suattr -C CAP_FOWNER,CAP_DEVICE_MGT,CAP_DAC_WRITE+ip -c "exec /sbin/getty ttyd1 co_9600" # port 1 t2:23:respawn:/sbin/suattr -C CAP_FOWNER,CAP_DEVICE_MGT,CAP_DAC_WRITE+ip -c "exec /sbin/getty -N ttyd2 console" # alt console |
| Caution: Redirecting the console by using the above method works only when the IRIX operating system is running. To access the console when the operating system is not running (miniroot) , you must physically reconnect the machine: unplug the serial hardware reset cable from the console/L1 port and then connect the console cable. |
If you use I/O fencing and then make changes to your hardware configuration, you must verify that switch ports are properly enabled so that they can discover the WWPN of the HBA for I/O fencing purposes.
You must check the status of the switch ports involved whenever any of the following occur:
An HBA is replaced on a node
A new node is plugged into the switch for the first time
A Fibre Channel cable rearrangement occurs

Note: The affected nodes should be shutdown before rearranging cables.
To check the status, use the following command on a CXFS administration node:
hafence -v |
If any of the affected ports are found to be disabled, you must manually enable them before starting CXFS on the affected nodes:
Connect to the switch using telnet.
Use the portenable command to enable the port.
Close the telnet session.
After the port is enabled, the metadata server will be able to discover the new (or changed) WWPN of the HBA connected to that port and thus correctly update the switch configuration entries in the cluster database.