This chapter discusses the following:
After completing these step discussed in this chapter, see Chapter 9, “Initial Configuration of the Cluster”. For details about specific configuration tasks, see Chapter 10, “Reference to GUI Tasks for CXFS”, and Chapter 11, “Reference to cmgr Tasks for CXFS”. For information about installing CXFS and Trusted IRIX, see Chapter 15, “Trusted IRIX and CXFS”. For information about upgrades, see “Rolling Upgrades”.
When you install the CXFS software, there are some system file considerations you must take into account. The network configuration is critical. Each node in the cluster must be able to communicate with every other node in the cluster by both logical name and IP address without going through any other network routing; proper name resolution is key. SGI recommends static routing.
The optional /etc/exports file on each node describes the filesystems that are being exported to NFS clients.
If the /etc/exports file contains a CXFS mount point, then when the system is booted NFS will export the empty mount point because the exports are done before CXFS is running. When CXFS on the node joins membership and starts mounting filesystems, the clconfd-pre-mount script searches the /etc/exports file looking for the mountpoint that is being mounted. If found, the script unexports the mountpoint directory because if it did not the CXFS mount would fail. After successfully mounting the filesystem, the clconfd-post-mount script will search the /etc/exports file and export the mount point if it is found in the /etc/exports file.
For more information, see “NFS Export Scripts” in Chapter 12.
This section discusses system files on administration nodes.
Edit the /etc/services file on each CXFS administration node so that it contains entries for sgi-cad and sgi-crsd before you install the cluster_admin product on each CXFS administration node in the pool. The port numbers assigned for these processes must be the same in all nodes in the pool.
The following shows an example of /etc/services entries for sgi-cad and sgi-crsd:
sgi-crsd 7500/udp # Cluster reset services daemon sgi-cad 9000/tcp # Cluster Admin daemon |
The cad.options file on each CXFS administration node contains the list of parameters that the cluster administration daemon reads when the cad process is started. The files are located as follows:
IRIX: /etc/config/cad.options
Linux 64-bit: /etc/cluster/config/cad.options
cad provides cluster information.
The following options can be set in the cad.options file:
| --append_log | Append cad logging information to the cad log file instead of overwriting it. | |
| --log_file filename | cad log filename. Alternately, this can be specified as -lf filename. | |
| -vvvv | Verbosity level. The number of v characters indicates the level of logging. Setting -v logs the fewest messages; setting -vvvv logs the highest number of messages. |
The default file has the following options:
-lf /var/cluster/ha/log/cad_log --append_log |
The following example shows an /etc/config/cad.options file that uses a medium-level of verbosity:
-vv -lf /var/cluster/ha/log/cad_nodename --append_log |
The default log file is /var/cluster/ha/log/cad_log. Error and warning messages are appended to the log file if log file is already present.
The contents of the /etc/config/cad.options file cannot be modified using the cmgr command or the GUI.
If you make a change to the cad.options file at any time other than initial configuration, you must restart the cad processes in order for these changes to take effect. You can do this by rebooting the nodes or by entering the following command:
# /etc/init.d/cxfs_cluster restart |
If you execute this command on a running cluster, it will remain up and running. However, the GUI will lose connection with the cad daemon; the GUI will prompt you to reconnect.
The fs2d.options file on each CXFS administration node contains the list of parameters that the fs2d daemon reads when the process is started. (The fs2d daemon manages the distribution of the cluster database (CDB) across the CXFS administration nodes in the pool.) The files are located as follows:
IRIX: /etc/config/fs2d.options
Linux 64-bit: /etc/cluster/config/fs2d.options
Table 8-1 shows the options can that can be set in the fs2d.options file.
Table 8-1. fs2d.options File Options
If you use the default values for these options, the system will be configured so that all log messages of level info or less, and all trace messages for transaction events, are sent to the /var/cluster/ha/log/fs2d_log file. When the file size reaches 10 MB, this file will be moved to its namesake with the .old extension and logging will roll over to a new file of the same name. A single message will not be split across files.
If you make a change to the fs2d.options file at any time other than the initial configuration time, you must restart the fs2d processes in order for those changes to take effect. You can do this by rebooting the CXFS administration nodes or by entering the following command:
# /etc/init.d/cxfs_cluster restart |
If you execute this command on a running cluster, it should remain up and running. However, the GUI will lose connection with the cad daemon; the GUI will prompt you to reconnect.
The following example shows an /etc/config/fs2d.options file that directs logging and tracing information as follows:
All log events are sent to:
IRIX: /var/adm/SYSLOG
Linux 64-bit: /var/log/messages
Tracing information for RPCs, updates, and transactions are sent to /var/cluster/ha/log/fs2d_ops1.
When the size of this file exceeds 100,000,000 bytes, this file is renamed to /var/cluster/ha/log/fs2d_ops1.old and a new file /var/cluster/ha/log/fs2d_ops1 is created. A single message is not split across files.
(Line breaks added for readability.)
-logevents all -loglevel trace -logdest syslog -trace rpcs -trace updates -trace transactions -tracefile /var/cluster/ha/log/fs2d_ops1 -tracefilemax 100000000 |
The following example shows an /etc/config/fs2d.options file that directs all log and trace messages into one file, /var/cluster/ha/log/fs2d_chaos6, for which a maximum size of 100,000,000 bytes is specified. -tracelog directs the tracing to the log file.
(Line breaks added for readability.)
-logevents all -loglevel trace -trace rpcs -trace updates -trace transactions -tracelog -logfile /var/cluster/ha/log/fs2d_chaos6 -logfilemax 100000000 -logdest logfile. |
This section discusses the cxfs_client.options file for IRIX and Linux 64-bit client-only nodes. For client-only nodes running other operating systems, see the CXFS MultiOS Client-Only Guide for SGI InfiniteStorage.
On client-only nodes, you can modify the CXFS client service ( /usr/cluster/bin/cxfs_client) by placing options in the cxfs_client.options file:
IRIX: /usr/cluster/bin/cxfs_client.options
Linux 64-bit: /etc/cluster/config/cxfs_client.options
The available options are documented in the cxfs_client man page.
| Caution: Some of the options are intended to be used internally by SGI only for testing purposes and do not represent supported configurations. Consult your SGI service representative before making any changes. |
The first line in the cxfs_client.options file must contain the options you want cxfs_client to process; you cannot include a comment as the first line.
For example, to see if cxfs_client is using the options in cxfs_client.options, enter the following:
irix# ps -ax | grep cxfs_client 3612 ? S 0:00 /usr/cluster/bin/cxfs_client -i cxfs3-5 3841 pts/0 S 0:00 grep cxfs_client |
Execute the following command on each node to reboot it:
# reboot |
The shutdown process then runs autoconfig to generate the kernel with your changes.
This section discusses the following:
For each private network on each node in the pool, enter the following, where nodeIPaddress is the IP address of the node:
# ping -c 3 nodeIPaddress |
Typical ping output should appear, such as the following:
PING IPaddress (190.x.x.x: 56 data bytes 64 bytes from 190.x.x.x: icmp_seq=0 tt1=254 time=3 ms 64 bytes from 190.x.x.x: icmp_seq=1 tt1=254 time=2 ms 64 bytes from 190.x.x.x: icmp_seq=2 tt1=254 time=2 ms |
If ping fails, follow these steps:
Verify that the network interface was configured up by using ifconfig. For example:
# ifconfig ec3 ec3: flags=c63<UP,BROADCAST,NOTRAILERS,RUNNING,FILTMULTI,MULTICAST> inet 190.x.x.x netmask 0xffffff00 broadcast 190.x.x.x
The UP in the first line of output indicates that the interface was configured up.
Verify that the cables are correctly seated.
Repeat this procedure on each node.
To test the reset connections, do the following:
Ensure that the nodes and the serial port multiplexer are powered on.
Start the cmgr command on one of the CXFS administration nodes in the pool:
# cmgr
Stop CXFS services on the entire cluster:
stop cx_services for cluster clustername
cmgr> stop cx_services for cluster cxfs6-8
Wait until the node has successfully transitioned to inactive state and the CXFS processes have exited. This process can take a few minutes.
Test the serial connections by entering one of the following:
To test the whole cluster, enter the following:
test serial in cluster clustername
cmgr> test serial in cluster cxfs6-8 Status: Testing serial lines ... Status: Checking serial lines using crsd (cluster reset services) from node cxfs8 Success: Serial ping command OK. Status: Checking serial lines using crsd (cluster reset services) from node cxfs6 Success: Serial ping command OK. Status: Checking serial lines using crsd (cluster reset services) from node cxfs7 Success: Serial ping command OK. Notice: overall exit status:success, tests failed:0, total tests executed:1
To test an individual node, enter the following:
test serial in cluster clustername node machinename
For example:
cmgr> test serial in cluster cxfs6-8 node cxfs7 Status: Testing serial lines ... Status: Checking serial lines using crsd (cluster reset services) from node cxfs6 Success: Serial ping command OK. Notice: overall exit status:success, tests failed:0, total tests executed:1
To test an individual node using just a ping , enter the following:
admin ping node nodename
For example:
cmgr> admin ping node cxfs7 ping operation successful
If a command fails, make sure all the cables are seated properly and rerun the command.
Repeat the process on other nodes in the cluster.
On administration nodes, the /etc/init.d/cxfs_cluster script will be invoked automatically during normal system startup and shutdown procedures; on client-only nodes, the script is /etc/init.d/cxfs_client . This script starts and stops the processes required to run CXFS.
To start up CXFS processes manually, enter the following commands:
On an administration node:
# /etc/init.d/cxfs_cluster start Starting cluster services: fs2d cmond cad crsd [ OK ] # /etc/init.d/cxfs start
On a client-only node:
# /etc/init.d/cxfs_client start Loading cxfs modules: [ OK ] Mounting devfs filesystems: [ OK ] Starting cxfs client: [ OK ]
To stop CXFS processes manually , enter the following command:
On an administration node:
# /etc/init.d/cxfs stop # /etc/init.d/cxfs_cluster stop
On a client-only node:
# /etc/init.d/cxfs_client stop Stopping cxfs client: [ OK ]
To see the current status of the CXFS processes, use the status argument. For example, the following output shows that the service is running:
# /etc/init.d/cxfs_client status cxfs_client (pid 3226) is running... |
The output in the following example shows that the service is stopped:
# /etc/init.d/cxfs_client status cxfs_client is stopped |
Beginning with IRIX 6.5.18f, SGI supports a policy for CXFS that permits a rolling annual upgrade. This policy allows you to upgrade a subset of the nodes in your cluster from IRIX 6.5.n to n+1 or n+4.
This policy lets you to keep your cluster running and filesystems available during the upgrade process.
The upgrade procedure makes use of a standby node, which is a server-capable administration node that is configured as a potential metadata server for a given filesystem, but does not currently run any applications that will use that filesystem. (In a later release, the node will be able to run applications that use other filesystems; however, this feature does not apply to this release.) After the upgrade process is complete, all nodes should be running the same release.
Each CXFS MultiOS Client release is paired with a given IRIX or SGI ProPack release; the MultiOS Client release will also support the same n+1, n+4 release set during an upgrade. For example, for IRIX, the MultiOS 2.3 release supports IRIX 6.5.18, 6.5.19, and 6.5.22. It is recommended that you upgrade all MultiOS Client nodes at least annually. For more information, see the product release notes and the CXFS MultiOS Client-Only Guide for SGI InfiniteStorage.
| Note: In production mode, CXFS supports a cluster running a single IRIX release and a single CXFS MultiOS Client, or a single SGI ProPack release and a single CXFS for SGI ProPack release. If you are running multiple IRIX releases and run into problems, you may have to bring all administration nodes to a single operating system release before the problem can be addressed. |
The following figures show an example upgrade procedure for a three-node cluster with two filesystems (fs1 and fs2 ), in which all nodes are running 6.5.18f.
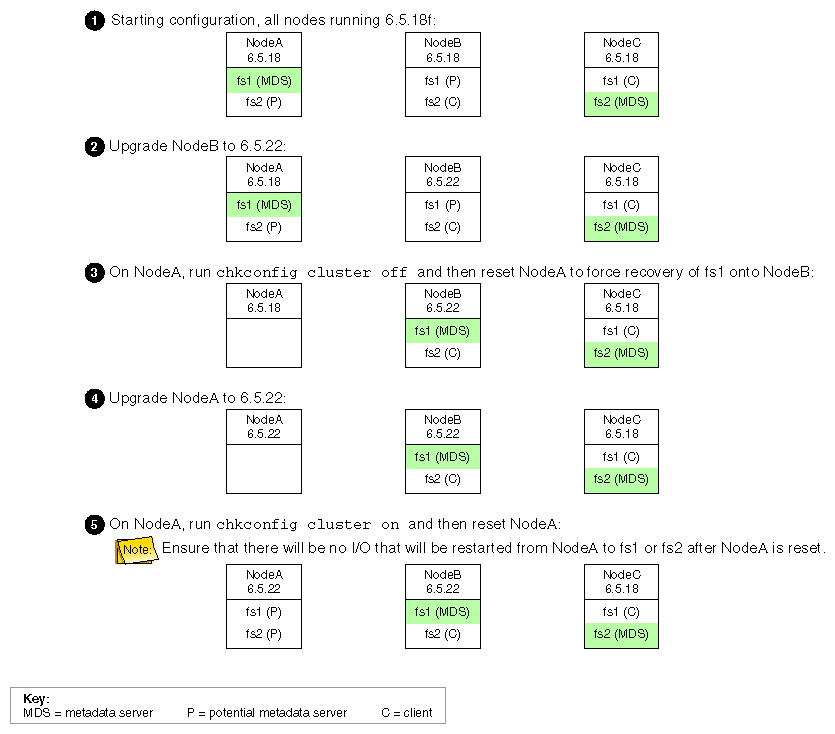
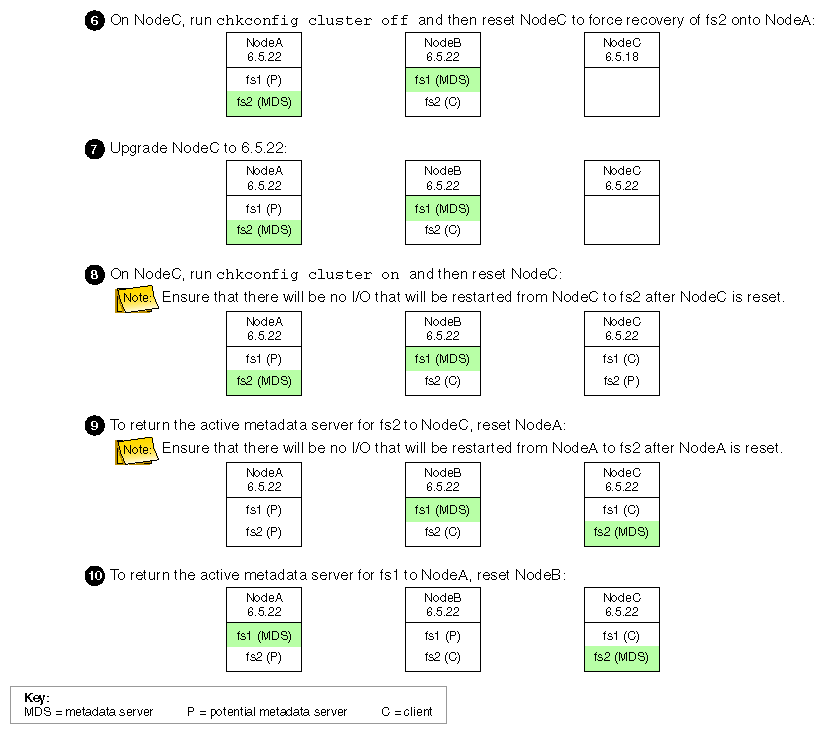
If you want nodes to restart automatically when they are reset or when the node is powered on, you must set the boot parameter AutoLoad variable on each IRIX node to yes as follows:
# nvram AutoLoad yes |
This setting is recommended, but is not required for CXFS.
You can check the setting of this variable with the following command:
# nvram AutoLoad |
The structure of the CXFS filesystem configuration was changed with the release of IRIX 6.5.13f. Upgrading to the 6.5.13f release provided an automatic conversion from the old structure to the new structure. However, if you are upgrading directly from 6.5.12f or earlier, (without first installing and running 6.5.13f), you must convert your CXFS filesystem definitions manually.
| Note: If you are upgrading from 6.5.13f or later, you do not need to follow the instructions in this section. Filesystems definitions are automatically and transparently converted when running 6.5.13f. |
After upgrading from 6.5.12f or earlier, you will notice that the CXFS filesystems are no longer mounted, and that they do not appear in the GUI or cmgr queries. To convert all of the old CXFS filesystem definitions to the new format, simply run the following command from one of the 6.5.14f or later nodes in the CXFS cluster:
# /usr/sysadm/privbin/cxfsfilesystemUpgrade |
After running this command, the CXFS filesystems should appear in the GUI and cmgr output, and they should be mounted if their status was enabled and CXFS services are active.
| Caution: This conversion is a one-time operation and should not be run a second time. If you make changes to the filesystem and then run cxfsfilesystemUpgrade for a second time, all of your changes will be lost. |
After all of the IRIX nodes in the cluster have been upgraded to 6.5.14f or later, it is recommended that you destroy the old CXFS filesystem definitions, in order to prevent these stale definitions from overwriting the new definitions if the cxfsfilesystemUpgrade command were to be run again accidentally. To destroy the old CXFS filesystem definitions, enter the following:
# /usr/cluster/bin/cdbutil -c "delete #cluster#clustername#Cellular#FileSystems" |